




近年来,人工智能理论、方法和技术快速发展,尤其是深度学习技术带动了智能任务的性能快速提升和在社会多个领域的成功应用。由于实际应用场景数据动态变化、多模态协同的特点,多模态人工智能成为人工智能理论方法发展的重要方向。多模态人工智能面向复杂动态多模态场景的数据理解、学习和推理,涉及自然语言处理、计算机视觉、模式识别、语音识别和多模态融合等领域。最近,人工智能大模型的发展和应用再人工智能领域产生了巨大的影响,也将在多模态人工智能中发挥关键作用。
为了给本领域研究者、技术开发人员和研究生介绍多模态人工智能前沿理论方法和最新进展,中国自动化学会模式识别与机器智能专业委员会主办这次前沿技术讲习班。讲习班于2023年9月22日-24日在昆明举办,由中国科学院自动化研究所刘成林研究员、华南理工大学金连文教授、云南大学信息学院张学杰教授和陶大鹏教授担任学术主任,邀请了多名人工智能领域的知名专家作报告,使学员在了解学科热点和基础理论方法、提高学术水平的同时,增进与多模态人工智能领域顶尖学者之间的学术交流。
主办单位:中国自动化学会模式识别与机器智能专委会
承办单位:云南大学信息学院
协办单位:云南云上云大数据产业发展有限公司
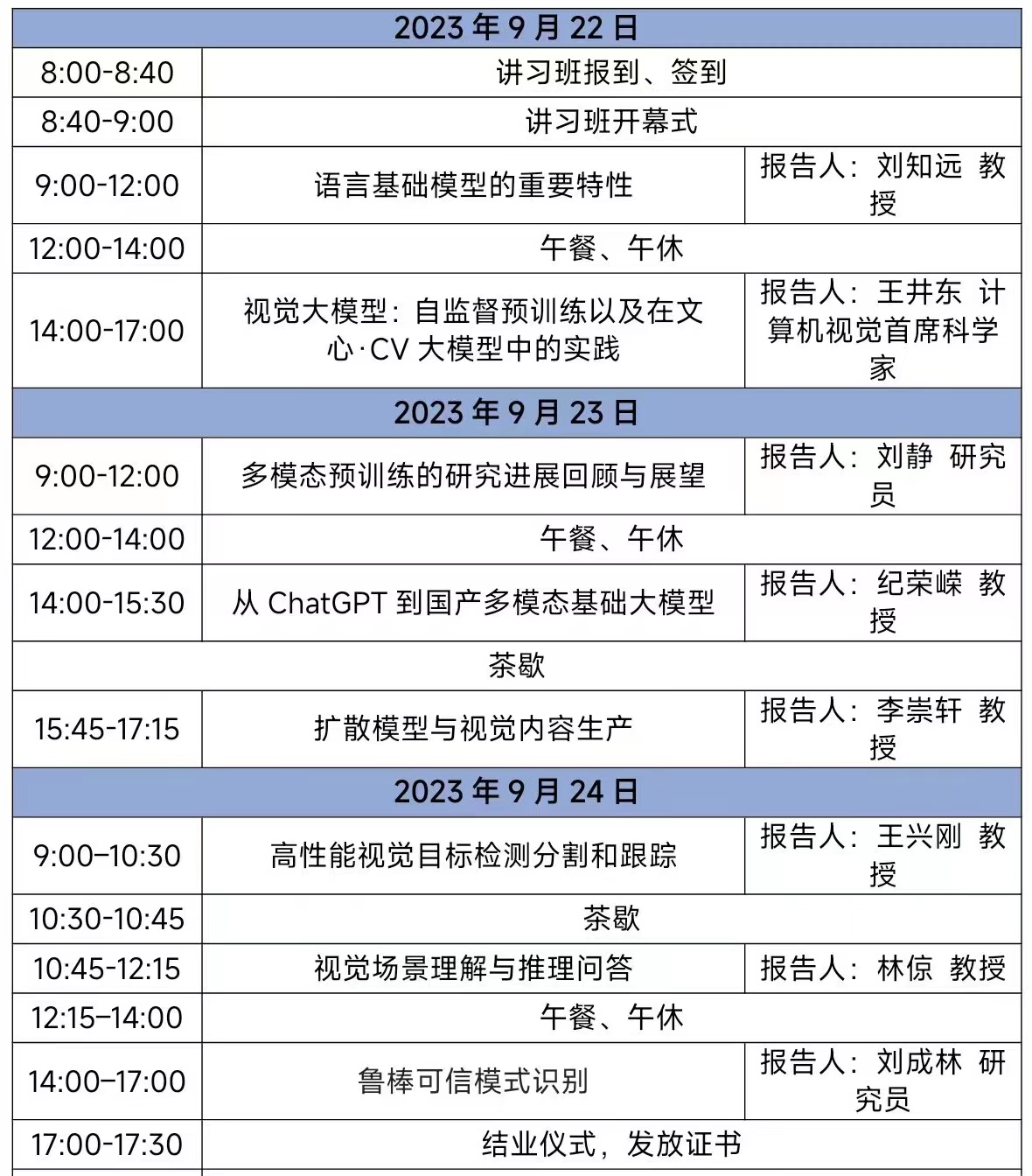
时间:2023年9月22号-24号
地点:云南省昆明市呈贡区南亚豪生酒店·南亚厅
注册费包括讲课资料和3天会议期间午餐。
注册链接:
https://www.cacpaper.com/register/76/user/preRegist
注册二维码:

简介:
简介:
金连文,华南理工大学二级教授,兼任广东省图像图形学学会理事长、中国图像图形学学会(CSIG)常务理事、CSIG文档图像分析与识别专委会主任、中国自动化学会模式识别与机器智能专委会常委委员等职。主要研究领域为人工智能、计算机视觉、文字识别、文档图像理解等,在重要学术期刊及国际会议上发表学术论文300余篇,其中SCI Q1区+CCF A类论文100余篇,Google Scholar论文被引用数12000余次,H-Index 58,获得授权发明专利70余项目。获省部级科技奖5项(其中一等奖2项,二等奖3项);指导学生参加权威国际国内学术竞赛荣获冠军20余次。
简介:
报告题目:
语言基础模型的重要特性
报告摘要:
近年来以BERT、GPT为代表的预训练语言基础模型,使人工智能技术进入“预训练-微调”的全新范式,特别是最近ChatGPT引爆了全社会对基础模型技术的关注。本报告重点介绍语言基础模型的基本原理,在智能能力方面体现的强大通用特性,在模型框架、微调适配、推理计算等方面体现的模块化计算特性,以及在多模态、工具学习、群体智能、安全性等方面体现的全新智能特性,并探讨大模型未来的研发应用范式。报告人简介:
报告题目:
视觉大模型:自监督预训练以及在文心·CV大模型中的实践
报告摘要:
本报告首先回顾计算机视觉领域里的自监督预训练算法最近几年的进展,包括对比学习和图像掩码建模等。其次,介绍文心·CV大模型中的自监督表征学习算法Context Autoencoder(CAE)和基于预训练的目标检测算法Group DETR等,同时,从学习物体部件的角度,给出几个典型的自监督预训练算法(BEiT、MAE、CAE、MoCo v3及DINO)的特点(TMLR)。再次,讲述基于CAE和Group DETR的工业视觉大模型、OCR文字识别大模型(MaskOCR)、人体大模型等。最后,分享图文对比预训练大模型在自动驾驶数据挖掘中的应用和基于多任务学习的交通感知大模型。
报告人简介:
报告题目:
多模态预训练的研究进展回顾与展望
报告摘要:
近年来,从预训练模型到预训练大模型,从文本、音频、视觉等单模态大模型,到现在的图文、图文音等多模态预训练大模型,无论在学术界还是企业界预训练模型都得到了广泛关注与爆发式发展。多模态预训练通过联合图文音等多模态内容进行模型学习,其发展在多模态理解、搜索、推荐、问答,语音识别与合成,人机交互等应用领域中具有潜力巨大的市场价值。本报告主要包含三方面内容:分析多模态预训练模型的重要性与必要性;回顾当前多模态预训练的最新研究进展;多模态预训练模型主要应用场景与未来展望。
报告人简介:
刘静,中科院自动化所研究员/博导,中国科学院大学岗位教授。研究方向多模态分析与理解,紫东太初大模型。曾获中国电子学会自然科学一等奖,图像图形学会科学技术二等奖,2022年世界人工智能大会“卓越人工智能引领者奖SAIL”。承担或参与多项国家自然科学基金项目、国家973课题、国家基金重大研究计划、国家重点研发等。已发表高水平学术论文150余篇,谷歌学术引用12000+次,SCI他引次数5000+次,其中有三篇被ESI列为Top1%高被引论文。在视觉计算相关领域的多项国际学术竞赛中荣获冠军10+项。
报告题目:
从ChatGPT到国产多模态基础大模型
报告摘要:
随着深度学习技术的快速发展,ChatGPT作为自然语言处理领域的重要突破,引起了广泛关注。本次探讨ChatGPT在自然语言处理领域中的重要性以及其所具有的优秀特性,继而引出国产多模态基础大模型的研发意义,以及如何通过结合多模态数据和深度学习技术来实现新型国产化基础模型的构建。具体来说,将讨论多模态数据的处理方法、模型构建的关键技术以及如何实现紧致化部署等相关技术点。本讲座的研究成果将为解决多模态大模型的部署难题和提高模型性能和效率提供借鉴和参考。
报告人简介:
报告题目:
扩散模型与视觉内容生产
报告摘要:
扩散模型与AIGC 摘要:扩散概率模型逐步地对先验分布去噪恢复数据分布。目前,这类模型在数据合成质量、采样的多样性和数据密度估计等指标下取得了超越 VAE、GAN、FLOW 等经典深度生成模型的结果,也部署于诸多的图像、跨模态大规模生成模型。本次报告会介绍扩散概率模型的基本原理、加速推断算法、大规模训练和可控生成等AIGC应用的前沿进展。报告人简介:
报告题目:
高性能视觉目标检测分割和跟踪
报告摘要:
视觉目标检测分割和跟踪技术是计算机视觉中的基础任务,具有重要的应用价值。本次报告将围绕视觉目标检测分割和跟踪技术,梳理近年来的技术发展路径,并从预训练大模型、开放场景感知、模型轻量化部署等方向做前沿技术介绍。
报告人简介:
报告题目:
视觉场景理解与推理问答
报告摘要:
近年来,以Transformer为核心的神经网络架构快速发展,网络规模日益庞大,并以此为基础推动了无监督/自监督学习技术的跳跃式发展,逐步形成一套被称为大模型或者基础模型的技术范式。本报告将梳理这套基础模型技术在视觉场景和推理问答中的应用。
报告人简介:
林倞,中山大学计算机学院教授/博导,国际模式识别学会会士(IAPR Fellow),英国工程技术学会会士(IET Fellow)。长期从事计算机视觉、机器学习及智能机器人领域的应用基础研究,承担国家2030科技创新重大项目。在国际顶级学术期刊和会议发表论文300余篇,论文被引用累计3万次;获权威期刊Pattern Recognition年度最佳论文奖,多媒体计算旗舰会议ICME最佳论文钻石奖,计算机视觉旗舰会议ICCV最佳论文奖提名;获中国图像图形学会科学技术一等奖、吴文俊人工智能自然科学奖,省级自然科学一等奖。中国科学院自动化研究所研究员
报告题目:
鲁棒自适应模式识别
报告摘要:
模式识别是人工智能领域的核心研究方向。传统的模式识别和机器学习假设闭合类别集、独立同分布、大数据训练。然而在开放环境下,包括深度学习在内的已有方法面临一系列新的技术挑战。尤其是,识别对象从闭合世界扩展到了开放世界,对新类别模式、异常和噪声模式的建模与处理成为困难,由此产生了开放集识别、置信度估计、持续学习等大量研究工作。本报告对开放环境模式识别的研究问题进行分析,并专门针对开放鲁棒性和类别增量学习进行深入讨论。主要内容包括:开放环境鲁棒模式识别的研究问题,开放集识别的模型和算法,深度模型置信度校准,类别增量学习,开放环境模式识别的未来发展趋势。
报告人简介:
联系人:李老师
联系电话:18403433440
电子邮箱: 20224053@ynu.edu.cn
