




导读:2025年8月16日,由中国自动化学会主办的2025中国自动化与人工智能教育大会暨2024-2025学年全国青少年劳动技能与智能设计大赛全国决赛在浙江桐乡召开。西安电子科技大学高新波教授受邀参加本次大会并作题为“人工智能崛起与教育变革”的报告。
在报告中,他介绍了人工智能的发展历程以及近期大模型取得的里程碑式成果,进而展望了人工智能未来的发展趋势,并深入探讨了人工智能时代教育面临的机遇与挑战,最后对教育变革的方向提出了自己的思考。
2025年4月,习近平总书记在上海考察时指出:“人工智能是年轻的事业,也是年轻人的事业。”本次活动举办的青少年劳动技能与智能设计大赛的开展,正是这一重要讲话的具体体现,即将“年轻人的事业”进一步延伸至小学阶段,充分彰显了国家对人工智能发展的高度重视。早在2018年,习近平总书记在中共中央政治局第九次集体学习时就强调,人工智能具有多学科综合、高度复杂的特征。这一观点与学界“多学科交叉”的理念相契合,表明人工智能的发展并非单一学科推动,而是建立在多学科交叉融合基础上的综合性科学。
从国际科研前沿来看,人工智能的地位也在持续上升。2024年度的诺贝尔物理学奖和化学奖均授予与人工智能相关的研究成果,凸显了人工智能在当前科学研究与创新中的重要作用。
与此同时,人工智能也在社会层面引发广泛关注。近三年来,每年春节期间的社会热点话题均与人工智能大模型密切相关:2023年春节前夕是ChatGPT的兴起,推动了大语言模型的广泛传播;2024年春节是Sora的出现,开启了文生视频的探索;2025年春节则主要由DeepSeek引发热议,让国人产生了强烈的振奋与共鸣。
一、人工智能的发端与崛起
人工智能的起点历来存在多种说法。部分学者认为应从M-P神经元模型算起;也有观点认为应追溯至1822年差分机的发明;还有学者认为,罗素与维特根斯坦提出的《逻辑哲学论》标志着人工智能进入人的思维层面,尤其是维特根斯坦所强调的“语言的边界就是世界的边界”,在今天大语言模型的兴起中得到印证,即人们能理解的世界局限于他们能用语言表达的事物,语言限制了人们的认知范围。从科学发展的角度来看,有人把1950年图灵提出“图灵测试”作为人工智能科学的正式起点,而1956年达特茅斯会议则更广泛地被视为AI的正式起点。人工智能的发展规律呈现出“首先技术取得突破,进而引发哲学思考,最终给出科学解释”的层层递进的特征,即技术往往先于科学而取得突破。
在1956年的达特茅斯会议上,麦卡锡、西蒙、Newell等与会者后来均获得了图灵奖乃至诺贝尔奖。这一会议表明,科学与技术的发展离不开青年学者的探索与贡献。当时的与会者大多尚处于学术早期阶段:麦卡锡时任助教,明斯基为初级研究员,而资历较深的香农仅短暂参会即离开了。由此可见,推动人工智能发展离不开青年群体的积极参与。从这一点上来看,开展青少年劳动技能与智能设计大赛具有相当的前瞻性与战略意义。
达特茅斯会议所提出的许多问题,至今仍未得到完全解决,但其学术前瞻性已得到广泛认可。人工智能的发展历程可概括为“三起两落”,即经历三次快速兴起与两次低谷波动,如图1所示。
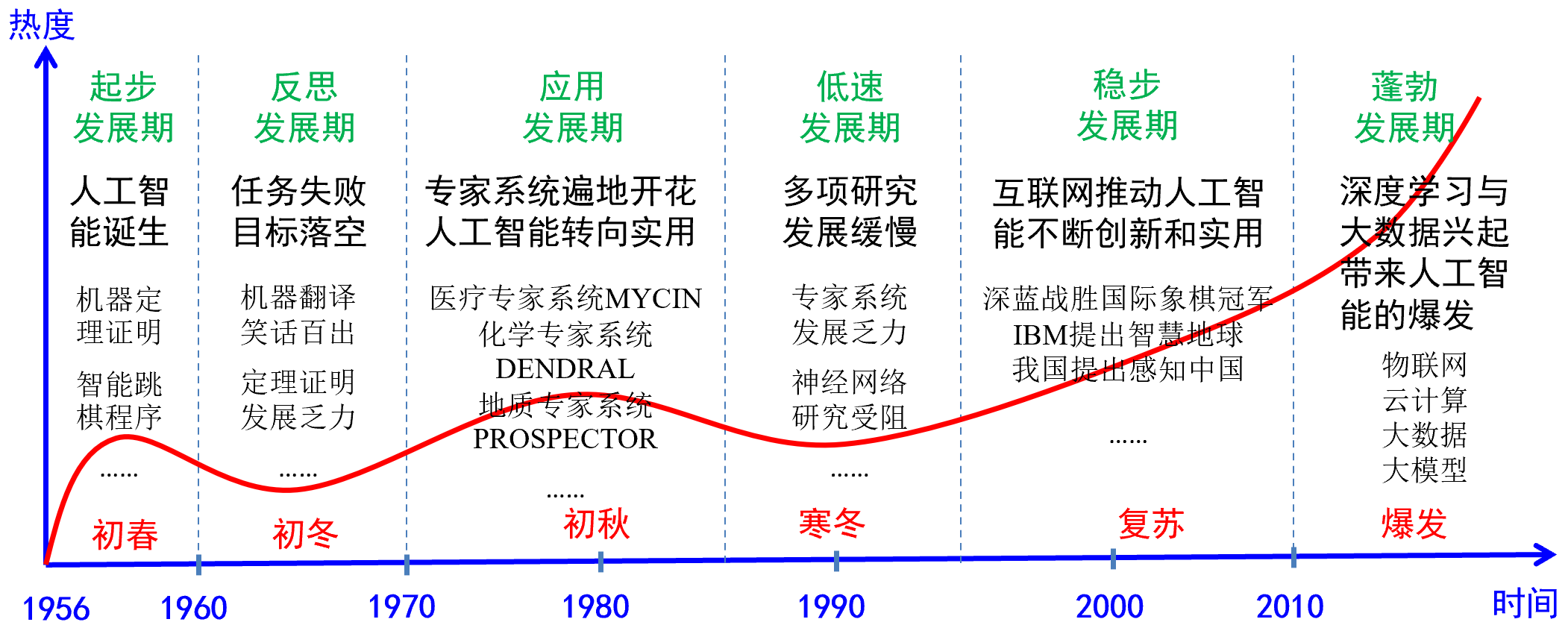
图1 人工智能的“三起两落”
整体而言,人工智能的发展大体经历了三个阶段:
第一阶段是逻辑推理阶段。西蒙与Newell的逻辑理论家程序曾成功证明怀特海的《数学原理》中的部分定理,体现了逻辑推理方法的潜力。
第二阶段是知识工程阶段。研究者开始关注人类逻辑思维之外的形象思维,并尝试将人类知识转化为人工智能的知识库。然而,由于专家知识难以形式化表达,甚至存在“只可意会不可言传”的困境,知识工程面临挑战。这一挑战推动了机器学习的兴起。
第三阶段是机器学习阶段。该阶段的发展进一步演进为神经网络与深度学习的突破。M-P模型最初的贡献在于能够完成线性可分的分类任务,然而该模型很快在非线性可分的分类任务上遇到瓶颈,人工智能进入了第一次低谷。此后,Hopfield提出的优化网络模型引入联想记忆与模式识别功能,也是因为这一成果使其获得诺贝尔奖。与此同时,单层感知机由于无法解决异或问题使研究陷入停滞,直至Rumelhart和Hinton 等人提出反向传播算法并提出了多层感知机,前馈神经网络研究才重新获得突破。随着隐含层数量的不断增加,人工智能正式进入深度学习阶段。Hinton等人在低谷中坚持不懈的研究,最终推动了该领域的重大飞跃。
深度学习阶段的第一个成功案例是卷积神经网络(Convolutional Neural Network, CNN),如图2所示。随后,我国学者何恺明、张祥雨、任少卿和孙剑提出了深度残差网络,并在ImageNet大赛中获得冠军。其意义不仅在于夺得冠军,更在于其分类准确率超越了人类水平。当时人类的错误率约为5.1%,而ResNet的错误率仅为3.6%,实现了超越人类的重大突破。此后,生成对抗网络的提出,使得人工智能具备了生成图像的能力,并在换脸等应用中得到广泛关注。
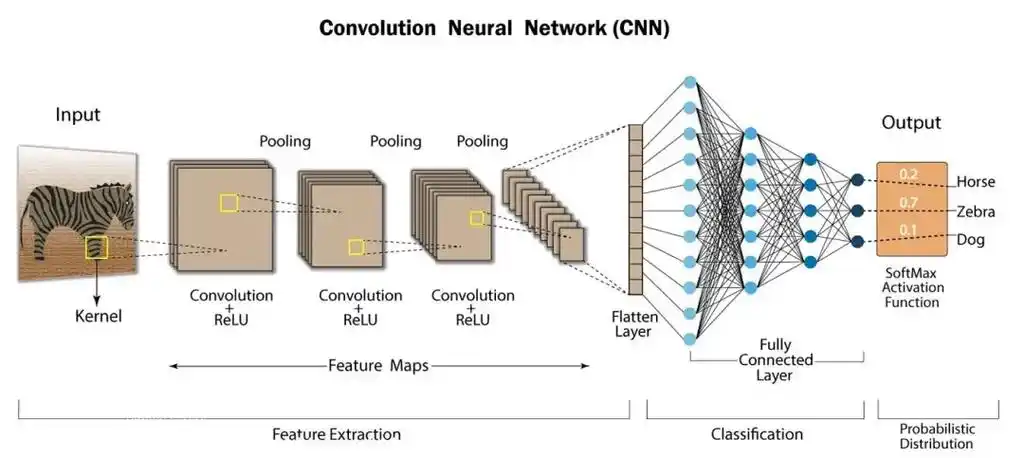
图2 CNN网络
随着网络架构的不断演进,研究者又引入了强化学习的概念,以进一步提升深度网络的性能,从而促成了大模型的诞生。近年来,大模型的发展取得了突破性进展。其演化大体经历了三个阶段:第一阶段是以CNN为代表的卷积神经网络;第二阶段是以Transformer为代表的新型神经网络结构;第三阶段则是以预训练模型为代表的GPT系列,标志着大模型时代的到来。
目前,大语言模型正在向多模态大模型过渡,不仅能够处理语言与文本,还可生成和理解图像、视频等多模态信息。在这一过程中,大模型的发展经历了如下八个里程碑:
第一,ChatGPT的问世,如图3所示。ChatGPT模型的出现被视为大模型的第一个里程碑。其能够与人进行较为自由的交流,被认为在某种程度上接近通过图灵测试,标志着人工智能在自然语言处理上的重大突破。

图3 OpenAI的ChatGPT
第二,Sora的发布,如图4所示。2024年2月,OpenAI推出Sora并发布了一段59秒的视频,生成了摩登女郎漫步东京街头的场景。然而,其中不少细节存在常识性错误,表明其尚未实现对真实物理世界的精确模拟。Sora的发布也引发了大模型的集中爆发。在同一天,Google发布了Gemini 1.5,Meta发布了V-JEPA,多家机构相继推出大模型,加速了全球范围内的大模型竞争。

图4 Sora大模型
第三,GPT-4o的推出,如图5所示。其中“o”意为“omni”。该模型不仅能处理多模态任务,还展现出一定的有温度的人机交互。例如在教育场景中,它能够在小朋友回答错误时,给予鼓励与提示,从而在一定程度上体现出“有温度的智能”。

图5 GPT-4o
第四,o1-preview的发布,如图6所示。2024年9月,OpenAI推出o1-preview版本。该模型在复杂推理方面实现了重大突破,尤其在编程和数学竞赛中表现突出。

图6 OpenAI o1-preview
第五,OpenAI o1+ChatGPT Pro的发布,如图7所示。相较于o1-preview,该版本功能更为完善、响应更快,并增强了多模态能力,成为当时全球最强大的人工智能模型。
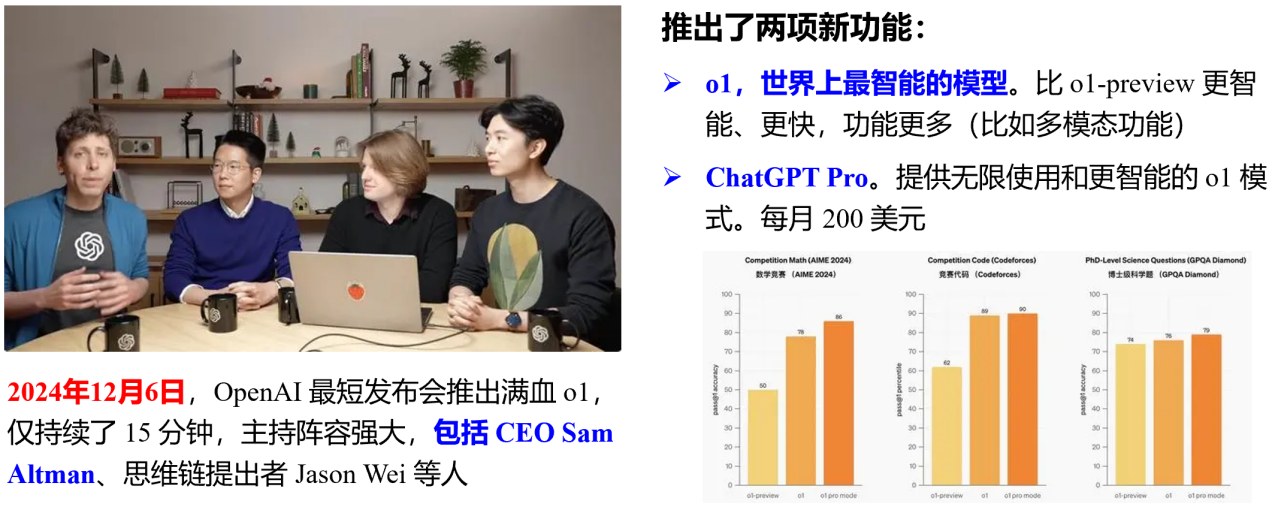
图7 OpenAI o1+ChatGPT Pro
第六,o3与o3-mini的推出,如图8所示。该版本实为o1的迭代升级,尽管未采用“o2”命名,但在欧洲部分运营商中被称作“o2”,最终定名为“o3”。在部分条件下,o3已表现出接近通用人工智能的能力。
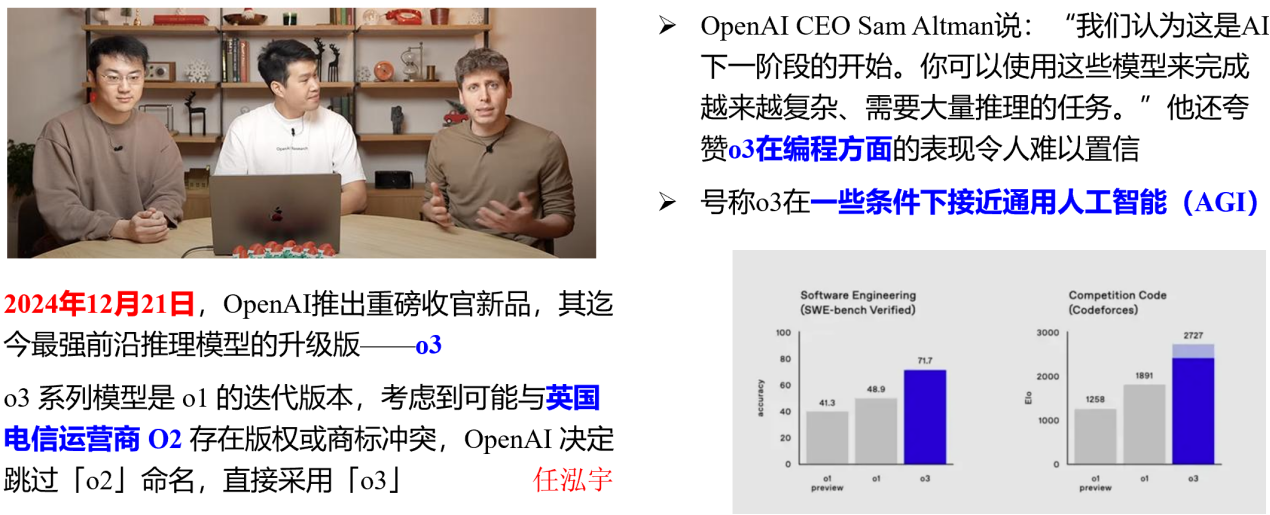
图8 OpenAI o3 + o3-mini
第七,DeepSeek的发布,如图9所示。2025年1月20日,DeepSeek R1正式发布,以极低成本实现了高性能,迅速登顶了北美免费应用App下载榜首,并对硅谷产业格局形成冲击。这一成果令国人倍感振奋,标志着中国在大模型领域取得了突破性进展。
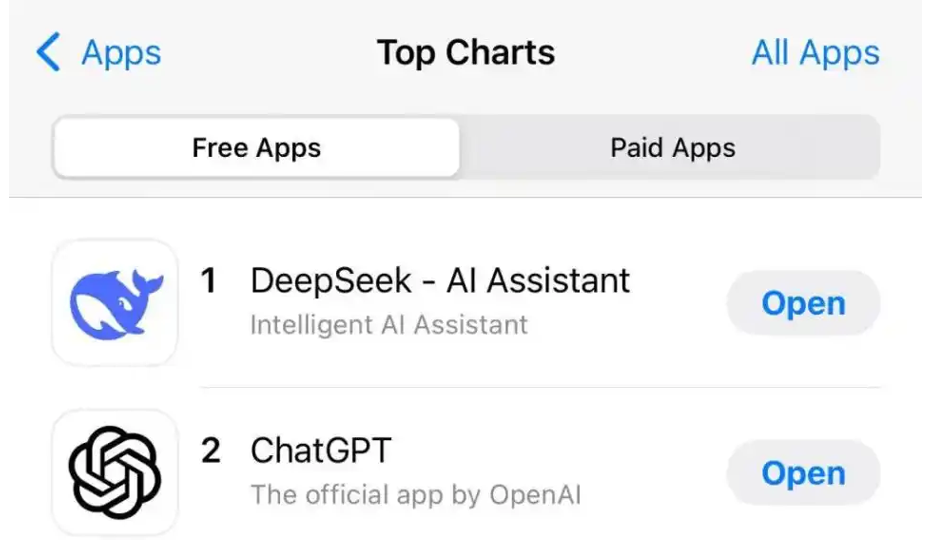
图9 DeepSeek
第八,GPT-5的问世,如图10所示。2025年8月8日凌晨,OpenAI正式发布GPT-5,被称为一体化智能系统。其在三大领域取得关键突破:显著降低了幻觉生成、提升了指令遵循精度、减少了迎合式回答。与此前版本相比,GPT-5展现出更高的可靠性与智能水平。
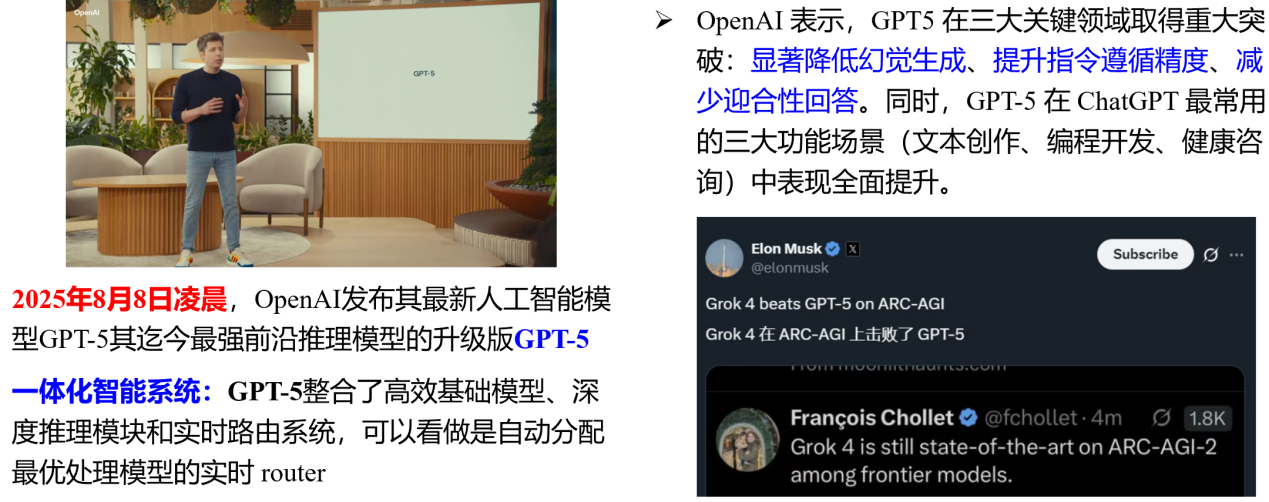
图10 GPT-5
二、DeepSeek崛起带来的启示
DeepSeek的出现可谓石破天惊,它以高性能、低成本和真开源模式,一举撼动了全球格局。英伟达的市值因此单日蒸发超过18%,微软、亚马逊云科技、英伟达等巨头也不得不在今年1月29日之后先后接入DeepSeek,因为它的免费开放使得闭源模式难以为继。可以说,DeepSeek不仅改变了产业格局,更极大提升了中国企业的自信心,打破了长期存在的“崇美症”和“恐美症”,激发了更多颠覆式创新的可能。事实证明,越自信越开放,越开放越成功,这与一些国家仍然奉行“小院高墙”的做法形成鲜明对比。
DeepSeek的创新之所以能够成功,背后有着独特的“三重秘密”,如图11所示。第一,它的团队中并没有大批海外留学背景的人才,很多都是刚毕业的学生,甚至有的还没有取得博士学位,却凭借“小天才的规模化”聚合,迸发出巨大的创造力。第二,它采取的是“华为式军团平推”的模式,从基础设施到底层硬件,从系统优化到模型算法,不是单点突破,而是全链条推进,保证了创新链条的整体联动。第三,它背后有一种原创性的思想指引,不是亦步亦趋地模仿西方,而是从本土文化与哲学中汲取力量,走出一条属于自己的创新道路。
图11 DeepSeek崛起的秘密
这种精神内核与电影《哪吒之魔童降世》(如图12所示)的主题不谋而合,正是“我命由我不由天”的理念,造就了DeepSeek的逆势崛起。这告诉我们,只要有坚定的信念和勇于尝试的勇气,就能够打破困境、逆天改命。此外,DeepSeek的成功带给我们诸多启示:算法与软件的协同优化,可以充分挖掘硬件的极致性能,从而在受限的算力条件下依然能取得突破;大模型还有巨大的改进空间,从算法、软件到系统架构都大有可为;技术创新不必完全追随西方,后发者同样能够定义规则,走出自主发展的道路。同时,人才的成长也并不依赖西方体系,中国的年轻人在本土实践中同样能够迅速成长、实现价值。更深层次地,东方文明所孕育的守正创新精神依然是推动科技进步的重要力量——在前路未明时的执着探索,在危机时刻的众志成城,在破局之后的开源共享,都是中华优秀传统文化蕴含的智慧。

图12 DeepSeek崛起与《哪吒》爆火
今天,当我们回顾DeepSeek的突破,也会让我们认识到教育同样需要自信与勇气,比如我所在的西安电子科技大学就在长期的办学过程中形成了以“院士校友多、将军校友多、航天总师多、所长总工多、创业英雄多”著称的人才培养“西电现象”。这充分证明了本土教育体系完全能够培养出顶尖的创新人才。这些事实说明,只要保持自立自强和文化自信,我们完全可以在人工智能的时代书写属于自己的篇章。
三、教育面临的挑战与机遇
大模型的发展正在深刻推动高等教育向个性化、智能化和全球化方向转型。它不仅改变了教学与科研的方式,更重新定义了师生关系与评价体系。因此,在积极应用人工智能技术的同时,高校必须保持清醒,平衡好效率与公平、技术与人文的关系,才能真正实现教育的价值,培养出适应未来社会的创新型人才。
在人工智能的赋能下,师生关系也正在发生深刻变化。教师的角色不再只是知识的传授者,而是逐渐回归为“人类灵魂的工程师”,更注重批判性思维、价值观和情感教育的引导;学生的自主学习能力将被大大释放,因为借助大模型,他们可以在课堂之外随时随地获取知识。与此同时,师生互动也突破了物理空间的限制,可以在虚拟环境中展开实时协作。学科结构也随之重构,传统学科正与人工智能深度融合,从医学中的AI辅助诊断,到法律中的智能合同审查,再到艺术中的AI创作,新的课程体系正在不断形成。教学模式也随之演化:个性化学习成为可能,虚拟助教提供支持,混合式教学逐渐常态化。而在科研方面,跨学科研究不仅成为可能,更成为必然。
教育评价体系也在转型,未来将不再仅仅依赖分数,而是贯穿整个学习过程,更注重能力导向——学生的批判性思维、创新能力和团队协作精神将被纳入核心指标,这些也正是用人单位真正看重的能力。同时,大模型也在推动教育的国际化发展,语言不再是障碍,跨语言学习、虚拟交换项目和教育资源共享将重塑国际教育格局。
更深层的变化在于学校的内涵与外延。未来的学校是什么?学生学什么、怎么学?教师怎么教?谁来教?这些都需要重新思考。学校将逐渐从封闭走向开放,学生在一所学校学习,获得的未必是这所学校的文凭,他们可以通过网络获得全球高校的课程与证书。而学校的价值更多在于提供学习条件、营造氛围和建立社群。在这样的格局下,教师真正成为陪伴者、激励者和组织者,而不再是单纯的知识传递者。甚至教师可能逐渐成为自由职业者,不受限于某一所学校,而是在更广阔的舞台上陪伴学生成长。
在人工智能时代,教育要重新理解“教”与“育”,如图13所示。“教”,强调知识与技能的输入,未来很大程度上可以由人工智能替代;但“育”,即人格、潜能与价值的培养,则永远无法由机器取代。教的是应知应会的知识,育的是真实独特的潜能;教的是进入社会的能力,育的是融入社会的层次;教是适应,育是张扬。教可以被技术完成,而育必须依靠人类教师去实现。

图13 人工智能时代教师角色的变化:从教到育
因此,在未来,学生依然需要学校,去学校不是单纯为了学习知识,而是为了交流与验证,去发现真正的自我。他们在学校获得的不是可复制的知识,而是不可替代的智慧——自信、选择、健康、沟通、提问、兴趣、分享,这些才是未来教育的重点。学校的实体场所不会消亡,只是功能将发生转变:它依然是培养创新力、促进情感交流、提供体验空间的独特场所,是人工智能无法替代的教育根基。
四、关于教育变革的初步思考
在人工智能时代,我们不能只当旁观者,而要躬身入局成为当局者,要做技术的推动者、应用的赋能者、伦理与治理的守护者、生态的共建者和风险的应对者。大模型正在深刻改变我们的生活与工作,高校更要准确认识和把握这一变革。我们既要有科学严谨的理性,也要有积极应变的勇气;既要保持开放心态,主动拥抱大模型,又要敢于求变,积极投身人工智能的创新实践。
因此,人工智能时代的高校治理必须随之转型。治理理念要从传统治理走向智慧治理,从依赖个别权威走向群体协同,从单纯经验转向数据驱动,从强调规范走向追求效能。人工智能和大数据使得这种转变成为可能,也要求我们构建一个更加开放、有弹性、同时又兼具人文关怀的治理格局。在这样的背景下,我们必须重新思考大学的存在价值:人才培养如何变革?科研范式如何重塑?文化传承如何创新?以及,如何保持人的独立自主性,避免对人工智能的过度依赖?这些都是亟待回答的问题。
面对变革,大模型时代的人才需要具备新的核心能力。第一是提问的能力。正如马克思所说,发现问题比解决问题更重要。提问不是笼统的,而是要学会分解问题、因人而异地提出创新性问题,并在反馈中不断修正。第二是使用工具的能力。人工智能归根到底仍然是工具,人类之所以成为人类,正是因为学会了发明和使用工具。今天,我们依然要掌握使用人工智能的能力。第三是跨界融合的能力。未来的知识不再是孤立的,必须具备跨学科、跨领域的整合与创新思维,才能真正驾驭大模型。
为了支撑这种能力的培养,教育本身也要适应新时代。首先要加强基础设施建设,算力与资源的分布决定了教育公平的格局,教育工具的普及是能否缩小差距的关键。其次要调整组织架构,过去学科分得过细,而人工智能时代要求的是融合,因此需要加快跨学科的教育教学改革。再次要重构课程体系,从通识教育到基础课程,从专业课程到实践课程,都要融入人工智能的思维与方法。
西安电子科技大学、西安交通大学、南京大学等都已经推出了人工智能的人才培养体系,从不同学科出发探索人工智能这一新兴交叉学科的建设路径。可以看到,未来的大学将在人才培养模式上深刻变革,努力实现大规模个性化成才的目标。未来的教育将会从单一的知识灌输走向定向培养,从僵硬的学科边界走向文理互通,从统一的教育内容走向基于个人兴趣和爱好的发展。
五、结语
DeepSeek的成功完全遵循了“创新、协调、绿色、开放与共享”的五大理念。因此,我们在工作中必须完整准确全面贯彻新发展理念。其次,面对大模型的崛起,我们必须保持理性认知,运用辩证唯物主义观点来看待大模型的发展,大模型也必须通过实践不断迭代与更新,才能真正认识、改造甚至生成客观世界。同时,我们还要全面理解数字经济的内涵,数字经济既包括数字产业化也包括产业数字化。因此,我们不能只关注前者而忽略后者,唯有以大模型推动传统产业的转型与升级,才能真正实现数字经济的繁荣与高质量发展。
*本文根据作者所作报告速记整理而成
嘉宾简介:
高新波,博士,教授,博士生导师,西安电子科技大学校长,国家级人才入选者,科技部中韩工业物联网“一带一路”联合实验室主任、教育部信息感知与传输重点实验室主任。现为第十四届全国政协委员,中国科协第十届全国委员会委员,教育部科技委委员、教学指导委员会委员,IEEE Fellow,中国电子学会、中国计算机学会、中国人工智能学会会士,中国图象图形学会杰出会员。主要研究方向:人工智能、机器学习、计算机视觉和模式识别。作为团队负责人分别入选教育部长江学者创新团队、科技部重点领域创新团队。主持国家自然科学青年科学基金(A类)等课题30余项,发表论文500余篇,出版专著、教材7部。获国家自然科学二等奖、全国创新争先奖,以及省部级科技一等奖5项。
