




导读:2025年12月14日,2025国家智能车发展论坛在江苏常熟举行。作为国家自然科学基金委员会信息科学部和中国自动化学会于2015年创办的品牌学术活动,本届论坛依托十年积淀的学术影响力,致力于搭建精准高效的产学研对接平台,成为智能车领域“理论创新-技术研发-产业落地”全链条交流的重要载体。
北京工业大学人工智能学院院长、教授,中国人工智能学会副秘书长马楠受邀参加本次论坛并作题为“无人驾驶具身交互智能”的报告。报告深入探讨了无人驾驶系统中车、路、人之间交互认知的必要性与实现路径,并指出真正的无人驾驶应具备完善的具身智能,以实现车与车、车与路、车与人之间的协同交互。通过“自主驾驶”与“交互认知”的双轮驱动,推动智能机器与人类社会的深度融合,使无人驾驶技术能够更好地服务于人类社会。
一、智能交互团队研究领域及历程
具身交互智能可理解为通过跨媒体感知、机器学习、认知计算与生成式人工智能等关键技术,构建与物理实体世界统一的智能表达与学习方法,使智能体能够在复杂多变的环境与任务中实现自主感知、行为理解、决策与智能协同,从而增强机器智能化呈现,促进人机融合。在该范式下,人的多种意图通过跨媒体交互从而被机器更好地理解,同时机器个体之间亦需通过信息共享与协同机制实现群体协作。因此,具身智能离不开与环境的持续交互,交互认知正是人机行为协同的重要保障,如图1所示。
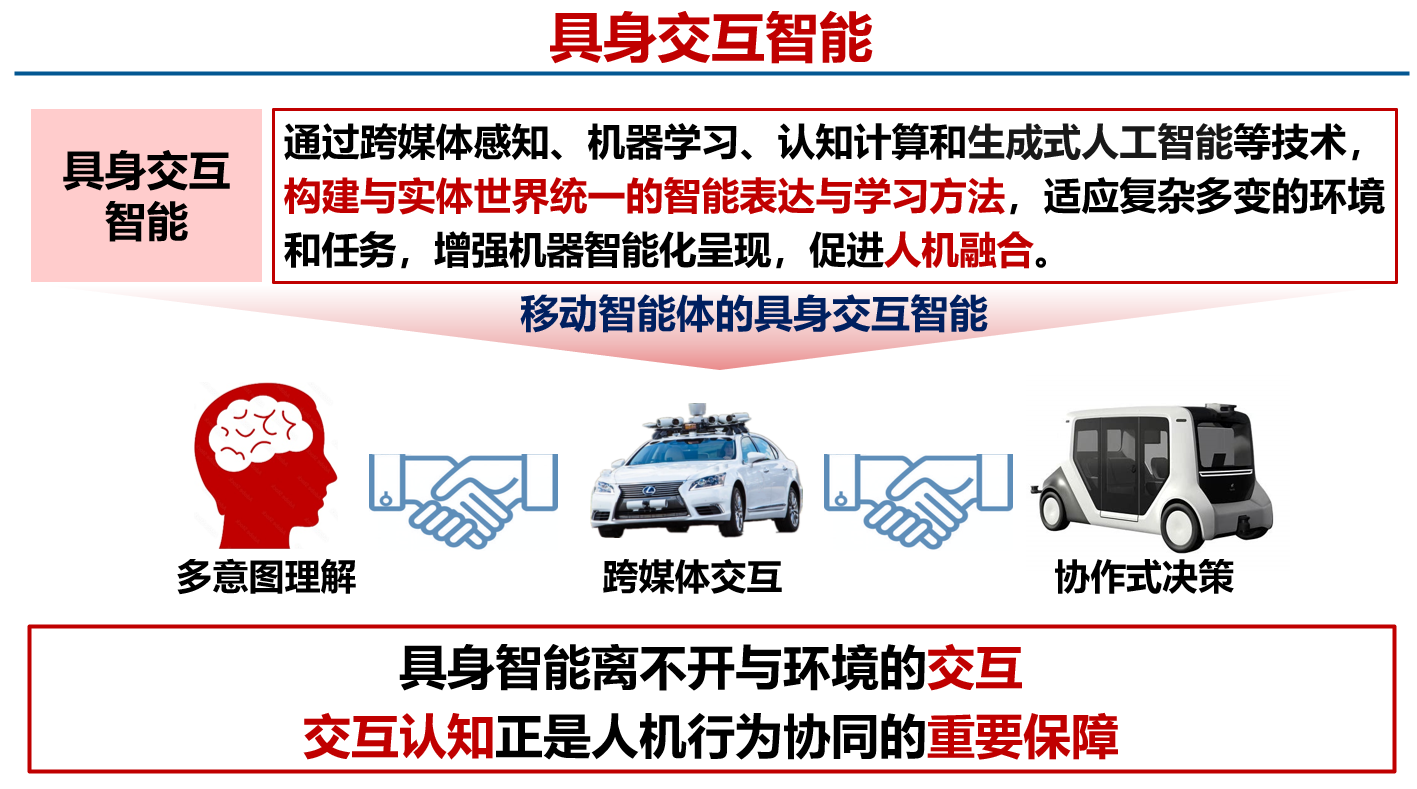
图 1 具身交互智能
近年来,国内外在异构感知数据特征提取与语义理解方面已开展了大量研究,尤其在复杂工况、恶劣环境以及极端与长尾场景下的人机协同、智能决策与控制等问题上,涌现出多篇发表于顶级期刊与会议的高水平成果。这些研究为具身交互智能在真实环境中的落地提供了重要理论与方法参考,也阐述了在具有不确定性、任务多样的现实场景中实现鲁棒感知与协同决策的关键挑战。
围绕以无人车为代表的移动智能体具身交互智能,团队长期开展系统性研究,重点面向智能驾驶、智能座舱,并进一步拓展至智能农业机器人等应用方向。多模态大语言模型被视为当前具身交互智能的重要核心驱动力,其在统一多源感知信息、理解复杂意图以及支撑多任务协同方面展现出显著优势。自2013年起,在李德毅院士的引领下,我组织成立了智能交互研究团队并持续发展,逐步形成了产学研融合的研究与应用体系。团队与多家企业保持长期合作关系,包括2015年郑州至开封宇通无人驾驶客车的实地测试,其车载智能交互系统由团队自主研发,同时还与北汽、东风、理想汽车等企业开展了多项联合研究与技术转化工作。
二、无人驾驶具身交互智能的基础架构与应用
在研究基础上,团队提出了无人驾驶具身交互智能(Embodied Interactive Intelligence Towards Autonomous Driving,简称EIIAD)。如图2所示,EIIAD建立了面向无人驾驶具身交互智能的基础架构与应用体系,该体系覆盖多维度、多主体的交互场景,形成了“人-车-环境”三位一体的交互框架,包括无人车与乘客之间的服务交互、与行人之间的意图交互、与驾驶员/安全员之间的协同控制交互,以及通过云端实现的与远程车主、运维人员及开发人员的远程交互,无人车与周边社会车辆之间的行为预测、意图理解与交互决策,无人车与道路基础设施、交通信号、路侧设备等智能交通系统的信息反馈与交互协同。这种多维度交互机制对于实现无人驾驶系统的安全性、可解释性与协同性具有关键意义。

图 2 无人驾驶具身交互智能架构
基于该体系架构,我们于2018年与北汽集团联合开发了人–车–路协同的无人驾驶云端智能交互系统,通过云端对无人驾驶车载数据进行统一管理,覆盖多种运行工况与复杂场景,并构建多维一体的智能交互功能框架。系统引入大语言模型服务中台,为工程化任务提供统一支撑,包括自动代码生成与系统运维辅助等功能。相关成果在中关村国际技术交易大会上进行了展示并获得百项新产品荣誉,并在东风Sharing-VAN、中通公交车、北汽福田图雅诺、欧马可等平台上实现了实际应用,同时也拓展至“云迹科技”移动服务机器人人机智能交互等领域。
在具体应用层面,研发了面向东风Sharing-VAN无人车超视距感知与智能交互编队控制系统,如图3所示。此外,研发的跨异构传感器配置、不同车辆平台的智能交互云控系统和智能网约无人车RoboTaxi于2018年北京国际车展期间顺义水上公园运行并向社会发布,为后续自动驾驶商业化应用奠定了技术基础。在产学研协同方面,团队还与天津大学合作开展无人驾驶公交车的智能交互与网联常态化应用开发,基于地理围栏技术实现智能语音播报、交互引导等功能,兼顾科研创新与工程落地需求。

图 3 超视距感知和智能交互编队控制方法
针对复杂动态环境下跨模态感知一致性与高精度定位难题,该方法构建了一种基于关键点融合位姿估计的跨模态点云协同感知框架,通过对多模态点云几何特征的高耦合建模与自适应筛选,联合局部关键区域聚合策略与全局模态一致性约束机制,实现了跨模态点云的高精度、强鲁棒配准。在连续运动条件下,系统定位精度达到约1.8 cm,相关研究成果被ICRA 2024 国际机器人会议录用,为具身交互智能系统在真实复杂环境中的自主感知与稳定运行奠定了坚实的感知智能技术支撑。
在主动感知方向,团队研究围绕实时激光雷达语义分割问题,提出了一种2D-3D表征交互增强的感知方法。该方法通过3D几何注入的方式将三维激光雷达信息映射到BEV和RV视角,通过多层级联合特征增强模块进行2D表征增强,这种动态交互增强的框架在保证实时性的同时显著提升了语义分割精度,成果被AAAI2026国际会议录用。实验结果表明,该方法在计算效率与分割精度方面均优于现有主流算法,验证了其在复杂环境感知中的有效性。
在主动感知研究的基础上,团队进一步面向复杂道路场景开展深入研究,重点聚焦矿区等存在凹坑、非结构化地面的极端作业场景。针对此类复杂智能道路场景的核心需求,团队创新性引入大语言模型,对底层感知结果进行高层次语义分析与综合推理,生成较精准的道路状态评估与分析报告;同时依托Qwen-VL模型搭建实验验证体系,开展了一系列智能道路理解与分析验证工作,最终实现了从底层多模态感知到高层语义认知的协同机制,形成了可验证、可迭代的技术闭环。
三、端到端无人驾驶具身交互智能
端到端无人驾驶方法通过深度神经网络直接接收来自多种传感器的信息输入,包括相机、激光雷达与GPS等信号,并直接输出车辆控制指令,如转向、制动与加减速等操作。通过多跳思维链生成系统化的推理步骤,无人车能够逐步分析和理解驾驶场景,综合考虑行人行为、环境状态及潜在交互工况,实现具有可解释性与更高安全性的决策过程。围绕上述研究,团队重点关注无人车在与环境及人类持续交互过程中的自主学习与行为优化。
团队提出并实现了端到端统一约束的车与环境交互模型(End-to-End Unified Constrained Vehicle Environment Interaction Model,简称UniCVE),该模型基于感知-认知-行为闭环反馈范式,以应对无人驾驶过程中不断出现的碎片化与长尾场景。如图4所示,UniCVE基于无人车与环境中行人和车辆交互异质性,设计针对不同对象定制的交互认知模块,并将该认知统一表达为无人车的状态价值网络,以生成符合社会交互规范的具身智能行为。具体而言,针对无人车与人类肢体语言的交互,我们提出了基于多视时空特征的超图神经网络动作识别方法,以精准地理解行人行为意图;对于无人车与车辆间的交互,我们提出了基于联合轨迹预测的世界模型深度强化学习网络,以实现与周围车辆的协同行为,如图5所示。最终,针对复杂的交互场景,我们借助大语言模型将人类的驾驶语言指导蒸馏到本模型中,在提升认知决策能力的同时,保持实时计算性能。UniCVE基于持续学习与在线更新机制,通过自成长实现从已知场景到未知环境与新型工况迁移的泛化能力。

图 4 端到端统一约束的车与环境交互模型框架
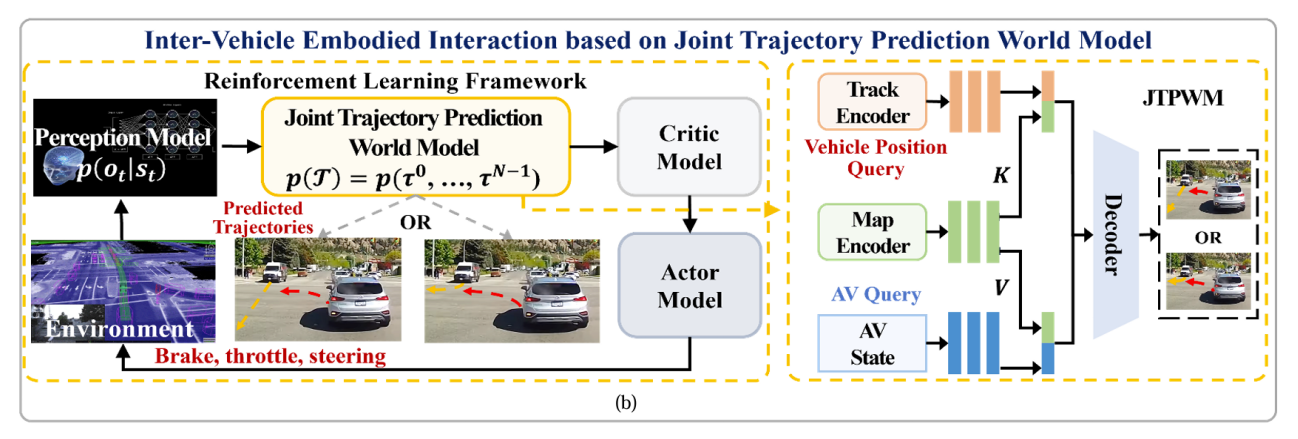
图 5 基于联合轨迹预测的世界模型深度强化学习网络
为实现端到端无人驾驶系统与人类价值观的深度对齐,团队进一步构建了面向价值对齐的人车在环无人驾驶增量式学习框架。该框架通过人车在环协同交互机制,将人类驾驶专家的价值判断嵌入端到端学习过程。具体而言,团队提出基于干预质量-场景难度课程设计框架,从人类专家实时接管与示范行为中提取隐含奖励函数实现价值对齐,并建立涵盖道路拓扑、天气复杂度、交互难度及学习进度的多维场景难度评估体系,设计渐进式训练课程以提升学习效率。为充分利用大规模离线专家驾驶数据,团队进一步提出增量式逆强化学习算法,通过挖掘离线数据集的隐含奖励机制,结合场景难度评估器构建学习进度自适应调控机制,实现从简单到复杂场景的策略优化。实验结果表明,相较于基线模型,系统成功率由约30%提升至60%,路线完成率达到91%,验证了人车在环价值对齐机制对提升系统安全性与决策可靠性的有效性。
团队将相关算法部署至东风无人驾驶巴士,在河北雄安新区开展规模化运营验证。截至目前,无人驾驶巴士累计行驶2.2万公里,完成4.5万次导航任务,涵盖公交接驳、复杂路口等典型场景,如图6所示, 充分验证了系统的类人驾驶能力与泛化性能。
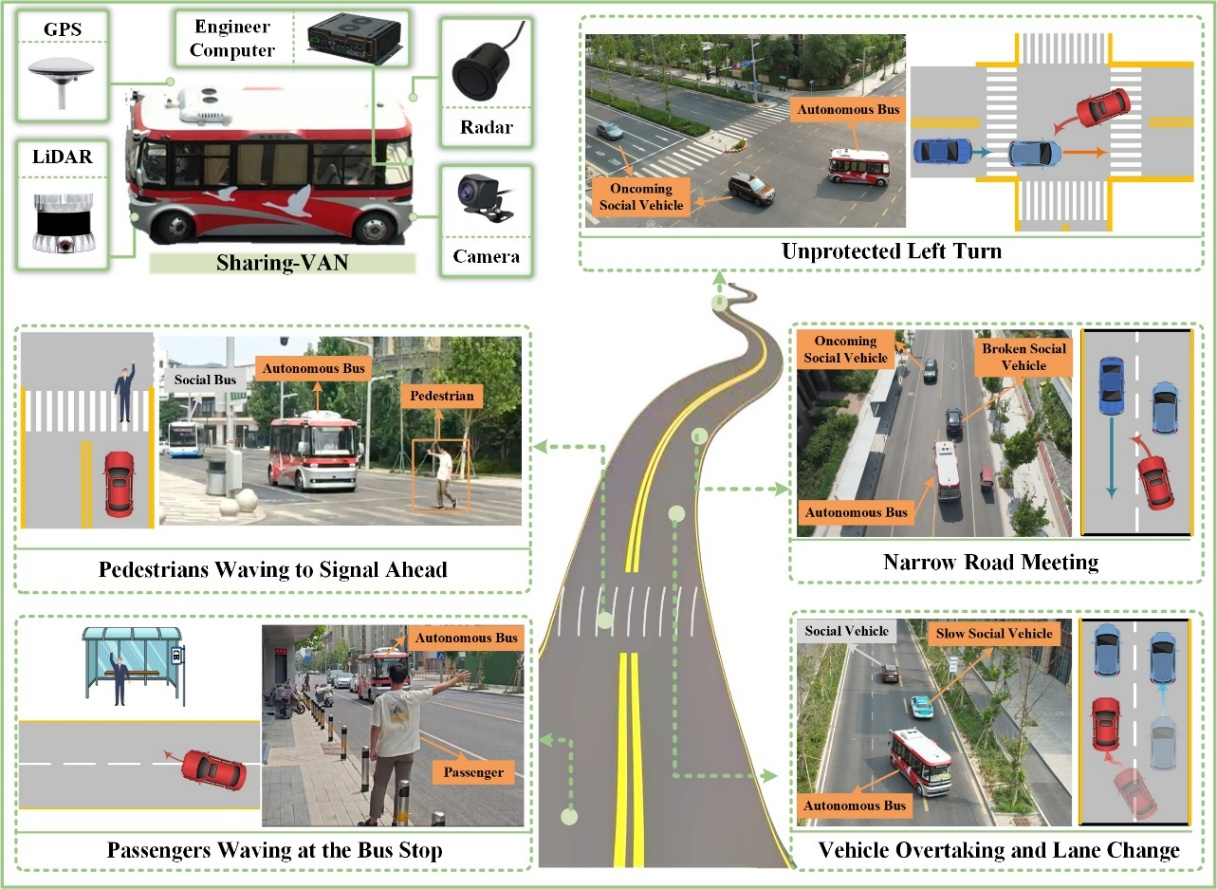
图 6 东风无人驾驶小巴运营路线
四、智能座舱的多模态具身交互
智能座舱是车与人交互高度密集的又一典型场景,其交互行为具有显著的时序特征与情境依赖性,涵盖通勤、休闲娱乐、导航与舒适性调节等多类驾驶与出行需求。要实现人性化的智能座舱体验,系统需要超越传统的“被动响应”,迈向主动的“意图理解与主动推送”。
智能座舱中的用户状态理解依赖于多源异构感知信息的统一编码,其中生理感知信息包括心电、呼吸、肌电与体温等信号,通过时间序列建模转化为结构化特征;心理感知信息则通过面部表情识别、语音情感分析、头部姿态估计与触觉反馈等方式获取,用于判断用户的注意力、疲劳程度与情感状态。
针对视、听、触多模态数据的统一表达问题,团队提出了双分支并行Transformer结构,实现视音频信息的高效融合与关键特征提取。该方法结合四音区语音编码与视听触信息的自适应融合机制,构建了覆盖通话、乘客交流、进食等典型行为的多模态座舱交互数据集,为后续的意图理解与主动服务提供统一的语义表示空间。
在完成跨模态编码后,团队研究聚焦个性化行为建模与主动推送机制。如图7所示,构建了融合常规行为字典与开放式行为增量的用户行为交互模型,完成了智能座舱用户行为主动/非主动交互事件判别,实现了时空超图序列分割的用户交互模式识别。针对新出现的行为模式,引入开放字典大语言模型建模方法,实现了低秩增量学习与语义扩展。

图 7 基于常规行为字典与开放式行为增量的智能座舱用户行为交互模型
在场景建模方面,将交互场景划分为单元场景与典型用车场景,对用户在座舱内产生的语音交互、界面操作、使用习惯及车控指令形成埋点记录,基于此提出基于多尺度时序超图驱动的场景识别方法,在不同时间粒度下同时捕获局部行为特征与全局交互模式,并通过超图结构学习用户行为在时空与语义层面的高阶关联。
基于个性化行为字典与实时多模态情绪分析,系统融合生理、视觉与语音信息,实现用户状态的综合评估与主动交互策略调整。通过预测用户潜在需求,在适当时机主动推送个性化服务,实现从"等待指令"到"主动服务"的范式转变。
团队成果已与理想汽车智能空间相关部门建立合作与共同开展工程应用。此外,团队构建了智能座舱人机交互评价系统,对多家主流车企车型进行系统评估,并形成了产学研协同制定的团体标准,相关标准已完成评审并进入发布阶段。
五、系统拓展与未来展望
在无人驾驶具身交互智能研究基础上,团队将感知智能和行为智能的核心技术拓展至其他移动智能体场景,典型应用之一为自主采摘作业机器人。由于无人驾驶系统对高精度定位与感知能力的需求,与移动采摘机器人在复杂环境中的感知与控制问题具有高度共性,团队将跨模态定位与感知方法迁移至农业机器人领域。相比无人驾驶,移动采摘任务面临更高难度,不仅要求机器人在运动过程中保持精准定位,还需在动态条件下完成果实采摘操作。
针对上述挑战,团队与中科原动力设计了末端环形执行器及配套采摘策略,通过旋转刀片实现果实切割,对果实位置估计与姿态感知提出了更高要求。为此,提出Top-Down Fusion Network(TDFNet)目标表型与姿态估计算法,将果实检测、关键点预测与成熟度分类进行联合建模,能够同时输出目标检测结果、成熟度信息及关键点位姿,并以“果实串”为单位构建完整的表型与姿态描述,如图8所示。

图 8 自主采摘作业机器人
围绕该研究,构建了虚拟仿真平台以缓解真实采摘环境难以复现的问题,并在翠湖农场开展生产测试,目前系统已进入小批量试制阶段,果实识别精度达到 91.25%。相关成果发表于机器人领域高水平期刊《IEEE Transactions on Robotics》及国际机器人会议 ICRA2024,并获得地方政府的高度关注与批示,相关应用实践有效锻炼了团队的工程能力与科研协同能力。
在实验平台建设方面,团队自主开发了多套具身智能研究平台,包括移动机器人感知计算单元、室内外导航定位系统及完整自主机器人平台,并基于此开展端到端的无人驾驶训练与闭环验证。未来,将进一步拓展跨模态主动感知能力,深化多源信息融合与高阶语义行为理解,持续推进人机交互中的价值对齐研究,并将相关技术拓展至车机协同、具身智能系统与智慧康养等应用领域。相关成果已在机器人与人工智能领域的顶级期刊和国际会议上发表。开放获取论文:https://doi.org/10.1016/j.eng.2025.09.032 https://doi.org/10.34133/research.0903.
在实验平台建设方面,团队在实验室内自主研发了一系列具身交互智能研究平台,包括移动机器人动静态感知智能与室内外3D导航系统、智能交互轮式机器人、端到端无人驾驶具身交互智能自主学习平台和实车系统,如图9所示。未来,团队将进一步拓展跨模态主动感知与智能推送,高阶语义行为理解以及从人机在环示教到自主探索进化成长范式的研究与应用,实现人机交互价值对齐,以赋能多个具身智能应用场景。

图 9 自主研发移动智能体科研实训平台
*本文根据作者所作报告速记整理而成
